Fourth-Year Design Project, Part 6: Fixing the Partitioned Guided Improvement Algorithm
In the previous post, we started our discussion on the partitioned guided improvement algorithm (PGIA). We covered some background information, an interesting idea our group developed, and how it fails for problems with more than two objectives.
In this post, we’ll conclude our discussion on PGIA. We’ll extend the algorithm for any number of objectives, cover an example problem with three objectives, and finally, discuss preliminary results and future work.
At this point, I will assume familiarity with multi-objective optimization, the guided improvement algorithm, and the previous post on PGIA. This post is likely the most difficult one in my blog series, so please feel free to ask questions in the comments.
Fixing the algorithm
When we concluded the previous post, we investigated the reasons why PGIA only worked with two objectives: dominating a locally optimal solution requires finding a solution in the “empty” region.
I’ve copied a diagram from my previous post, where we’ve found a Pareto point and split the search space into four regions. The solution in Region B can only be dominated by solutions in Region B or Region D; specifically, the patterned area in the diagram. If the solution we found is locally optimal, then there is no better solution in Region B. Additionally, there is no better solution in Region D because nothing dominates the originally discovered Pareto point.

The problem with three or more objectives is that we cannot easily make this guarantee.
Let’s look at the general problem with N metrics that we want to maximize,
(m1, m2, …, mN). Suppose the first
Pareto point we find is P = (p1, p2,
…, pN). When we split the space, we get 2N
regions. Each region is described by constraints of the form
{(m1, m2, …, mN) such that m1
■ p1, m2 ■ p2, …, mN
■ pN}, where ■ is ≥ for “better than or equal” or
< for “worse than”. For shorthand, I’ll simply write
(■p1, ■p2, …,
■pN). Keep in mind that mi represents
the ith metric and will vary, while pi represents
the ith metric value and is fixed.
The (dominated) region described by the constraints (<p1, <p2, …, <pN) is excluded since all solutions within that region are dominated by P. The (empty) region described by the constraints (≥p1, ≥p2, …, ≥pN) is excluded since there are no solutions that dominate P, by definition of a Pareto point.
Let’s look at the regions directly “adjacent” to the empty region, that is,
regions with exactly one “worse than” constraint. The following argument will be
the same for all N of these regions, so we’ll simply consider the region with
constraints (<p1, ≥p2, …,
≥pN), where the remaining constraints are
≥pi.
For any given solution within this region, a dominating solution exists if we improve at least one of the metrics (and satisfy the problem constraints).1 If we increase only the objectives m2, m3, … mN, we will remain in this region. In contrast, if we increase m1, we will eventually reach a different region, the one described by constraints (≥p1, ≥p2, …, ≥pN).
In other words, any locally optimal solution in (<p1, ≥p2, …, ≥pN) might be dominated by a solution in (≥p1, ≥p2, …, ≥pN)., but since that region is empty, all locally optimal solutions in (<p1, ≥p2, …, ≥pN) are globally optimal.
The same argument applies to the other regions with exactly one “worse than” constraint. Since all these regions are independent2 and do not overlap each other, we can search them in parallel.
Suppose we have gone and found all locally optimal solutions in the N regions
with exactly one “worse than” constraint. We know that these solutions are
globally optimal.
Now let’s look at the regions with exactly two “worse than” constraints. Without loss of generality, we’ll consider (<p1, <p2, …, ≥pN), where the remaining constraints are ≥pi. Using a similar argument from before, if we want to find a better solution in a different region, we have to increase m1, m2, both. This pushes us into one of the following regions (<p1, ≥p2, …, ≥pN), (≥p1, <p2, …, ≥pN), or (≥p1, ≥p2, …, ≥pN).
We already know the last one is empty. However, at this point, we’ve already found the locally optimal solutions in (<p1, ≥p2, …, ≥pN) and (≥p1, <p2, …, ≥pN). We can use those solutions to create exclusion constraints for our search in (<p1, <p2, …, ≥pN), thus avoiding locally optimal solutions that are dominated by external solutions. In other words, we can guarantee that locally optimal solutions in (<p1, <p2, …, ≥pN) are globally optimal.
We can apply the same argument to all regions with exactly two “worse than”
constraints and search them in parallel. Once these regions are done, we can
search all regions with exactly three “worse than” constraints, then four, and
so on until we finish with N - 1 “worse than” constraints.3 At every step of this process, we can guarantee locally
optimal solutions are globally optimal by using exclusion constraints based on
all previously found optimal solutions.
Our algorithm now has multiple steps with dependencies, which will require sequential processing. However, we have still broken the problem into smaller pieces, and we can still perform some of the searching in parallel. We just cannot search all 2N regions in parallel.
An optimization and some more notation
Consider the regions (≥p1, ≥p2, …, <pN) and (<p1, <p2, …, ≥pN), where the former has exactly one “worse than” constraint and the latter has exactly two “worse than” constraints. From our previous description, we have to finish searching in the first region before we can start searching in the second region, because it has fewer “worse than” constraints.
However, these two regions are independent. Region (≥p1, ≥p2, …, <pN) depends only on (≥p1, ≥p2, …, ≥pN), while region (<p1, <p2, …, ≥pN) depends only on (≥p1, <p2, …, ≥pN), (<p1, ≥p2, …, ≥pN), and (≥p1, ≥p2, …, ≥pN). In other words, we can search these two regions in parallel. No solution in one can dominate a solution in the other.
We can create a dependency graph that illustrates which regions we can search in
parallel. However, our current notation is a little difficult to work with, so
we’ll use binary strings, similar to how our implementation uses bit sets. The
binary string b1b2…bN, represents
a region (■p1, ■p2, …,
■pN) where bi is 1 for “better than
or equal” constraints and 0 for “worse than” constraints.
Our dependency graph will be a directed acyclic graph where each vertex
represents a region, and an edge directed from R to R′ means
R is a dependency of R′. In other words, we need to search in
R before we can search in R′, because a solution in R might
dominate a locally optimal solution in R′.
For a problem with N objectives, our graph will have 2N
vertices, where each vertex is labelled with a binary string of length N.
A directed edge from R to R′ exists if and only if
R′ is the same string as R, but with exactly a single 1 changed
to a 0.
Let’s examine why this works. Suppose the 1 we changed to a 0 corresponds to
the digit bi, which represents metric
mi,. The edge from R to R′ means R is
a dependency of R′, or that a solution in R might dominate
a locally optimal solution in R′. Assuming we can satisfy the
problem constraints, we can find this better solution in R by taking the
solution in R′ and setting mi to be greater
than or equal to pi.
It is also possible to find a better solution by increasing multiple metric
values. This would correspond to changing multiple 0s to 1s. However, the
dependencies and the “dominates” relationship are transitive; if solution A is
dominated by solution B and solution B is dominated by solution C, then solution
A is dominated by solution C.
Remember, the key idea for this algorithm is that we search the dependencies in order, and then use the known Pareto points to construct exclusion constraints. Therefore, when we search within a region, we exclude any locally optimal points that we know are dominated. The remaining locally optimal points are globally optimal, because we did not find anything that could dominate them.
An example problem with three objectives
To visualize how this algorithm works, we’ll walk through an example problem with three objectives. This example problem is based on the one from the previous post, but slightly modified for demonstration purposes.
First, we’ll consider all existing solutions, even non-optimal ones. We will assume that the first Pareto point, P = (10, 11, 9), has already been found, and that we have already split the space accordingly. This time, the regions are labelled with binary strings instead of letters.
| Region | Constraint | Metric points of solutions |
|---|---|---|
| 0004 | (<10, <11, <9) | (5, 6, 4) |
| 001 | (<10, <11, ≥9) | (9, 8, 12) |
| 010 | (<10, ≥11, <9) | (7, 13, 8) |
| 011 | (<10, ≥11, ≥9) | (5, 12, 10), (6, 12, 12) |
| 100 | (≥10, <11, <9) | (11, 10, 8), (14, 10, 8) |
| 101 | (≥10, <11, ≥9) | (11, 9, 10) |
| 110 | (≥10, ≥11, <9) | (11, 14, 8) |
| 111 | (≥10, ≥11, ≥9) | None; no solutions dominate P |
The dependency graph for this problem is shown below. For completeness, I have
additionally included the vertices for 111 and 000, even though we skip them
in the algorithm.

Since 111 is empty, we start by searching 110, 101, and 011 in parallel.
In 110 and 101, the only solutions are (11, 14, 8) and (11, 9, 10),
respectively. Therefore, these solutions are locally optimal. In 011, we first
find that (6, 12, 12) is the locally optimal solution, dominating (5, 12,
10), since it has improved at least one metric value without worsening the
others. Specifically, the first and third metric values are better, while the
second value is no worse.
The locally optimal solutions we discovered are also globally optimal, because
any better solution from a different region must exist in 111, which is empty.
If we finished 110 and 101 first, the dependency graph indicates we can
proceed to 100, even though we could still be searching in 011. This is
because no solution in 100 can dominate a solution in 011, and vice versa.
We could not make a metric better without making some other metric worse.
Suppose we have finished searching 110, 101, and 011, and we have the
corresponding exclusion constraints to search in 001, 010, and 100.
In 001, we find the solution (9, 8, 12), which is locally optimal and not
dominated by the known solutions. Therefore, it is globally optimal.
In 010, the exclusion constraints prevent us from returning (7, 13, 8) as
a solution, because it is dominated by (11, 14, 8). Thus, there are no locally
optimal solutions in this region.
Finally, in 100, the exclusion constraints prevent us from yielding (11, 10, 8).
However, nothing excludes (14, 10, 8), so it is both locally and globally
optimal.
In the diagram below, I have plotted the three-dimensional graph, without solutions. Note the two regions shaded grey; the darker region is excluded because all solutions are dominated by P, and the lighter region is excluded because there are no solutions that dominate P.
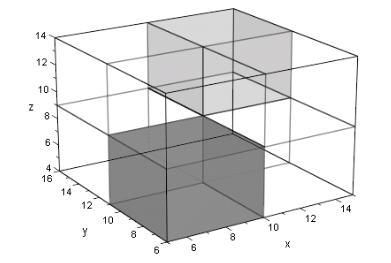
I plotted this graph with MATLAB (specifically, MuPAD). The code is provided below, and I have also included the code for plotting the solutions.
plot(
plot::Box(10..15, 11..16, 9..14, FillColor=RGB::Grey80.[0.8]),
plot::Box(10..15, 11..16, 4..9, Filled = FALSE),
plot::Box(10..15, 6..11, 9..14, Filled = FALSE),
plot::Box(10..15, 6..11, 4..9, Filled = FALSE),
plot::Box(5..10, 11..16, 9..14, Filled = FALSE),
plot::Box(5..10, 11..16, 4..9, Filled = FALSE),
plot::Box(5..10, 6..11, 9..14, Filled = FALSE),
plot::Box(5..10, 6..11, 4..9, FillColor=RGB::Grey50.[0.8]),
/* These are the (globally) optimal solutions */
plot::PointList3d(
[[9,8,12], [6,12,12], [14,10,8], [11,9,10], [11,14,8]],
PointStyle=FilledSquares),
/* These solutions are not globally optimal */
plot::PointList3d(
[[5,6,4], [7,13,8], [5,12,10], [11,10,8]],
PointStyle=FilledCircles)
)Preliminary results
Our group has implemented both the algorithm and the optimization described above. I will not be discussing the implementation this time,5 but you can find the code on GitHub.
With our implementation, we have been able to run our preliminary tests. Below, we have a graph and a table comparing incremental solving (IGIA), checkpointed solving (CGIA), the overlapping guided improvement algorithm (OGIA), and PGIA.
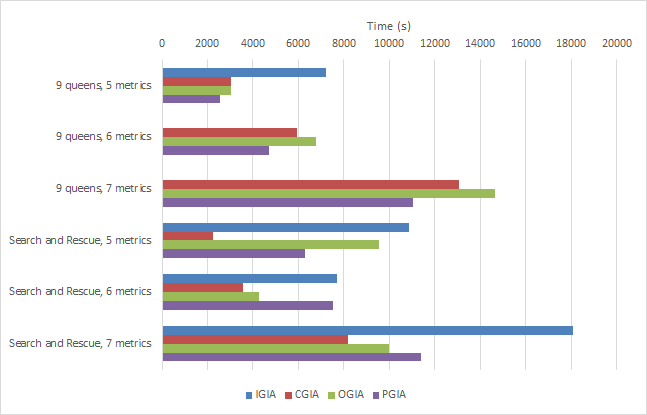
In the graph, lower numbers are better, indicating that less time was spent solving the problem. Also, note that two of the queens problems are missing a bar for IGIA; for one of them, we never attempted the test, and for the other, the bar distorts the entire graph because it is so large. The original GIA results are not included, since we are now comparing our algorithms against IGIA. Finally, recall that these are informal test results, run on the undergraduate computer science servers.
| Problem | IGIA | CGIA | OGIA | OGIA |
|---|---|---|---|---|
| 9 queens, 5 metrics | 2 hours, 0 min | 51 min | 50 min | 42 min |
| 9 queens, 6 metrics | 4 days, 16 hours, 43 min | 1 hour, 39 min | 1 hour, 53 min | 1 hour, 18 min |
| 9 queens, 7 metrics | Never attempted6 | 3 hours, 37 min | 4 hours, 4 min | 3 hours, 4 min |
| Search and rescue, 5 metrics | 3 hours, 0 min | 1 hour, 26 min | 2 hours, 38 min | 1 hour, 44 min |
| Search and rescue, 6 metrics | 2 hours, 8 min | 59 min | 1 hour, 11 min | 2 hours, 5 min |
| Search and rescue, 7 metrics | 5 hours, 1 min | 2 hours, 16 min | 2 hours, 46 min | 3 hours, 10 min |
The results are similar to OGIA, though in some cases PGIA can be better or worse. Again, we also see that CGIA, a single-threaded approach, beats PGIA, a multi-threaded approach, in some of the tests.
However, when we tried some of our extremely large tests, CGIA and OGIA fell behind.7
| Problem | CGIA | OGIA | PGIA |
|---|---|---|---|
| 9 rooks, 5 metrics | 21 days, 9 hours, 36 min | 5 days, 8 hours, 16 min | 4 days, 15 hours, 28 min |
| 9 rooks, 6 metrics | Never attempted8 | 16 days, 11 hours, 56 min | 5 days, 17 hours, 19 min |
| 9 rooks, 7 metrics | Never attempted | 19 days, 39 min | 5 days, 15 hours, 52 min |
We suspect this extremely poor performance is because the rooks problems have fewer constraints than the queens problems. Thus, there are far more solutions to find, and PGIA can better handle this situation. However, it’s important to note that these problems are extremely large and contrived, which we likely won’t see with real world problems.
Future work
At the time of writing, we are interested in three further improvements to PGIA.
The first, similar to OGIA, is to build PGIA on top of CGIA. Again, we would need to look at reducing memory usage first.
Next, we could recursively split the regions. To keep things simple, our first implementation only splits the space once, and uses regular GIA within each region. We’re interested in what happens if we continue splitting the regions and making them smaller. However, we probably want to limit the number of recursive calls, otherwise there will be too much overhead.
Finally, we’re interested in whether we can find a “good” Pareto point to split the space. Currently, we take whatever Pareto point we find first. However, this may result in regions with different sizes. It may be more effective for us to choose a Pareto point that gives us regions with roughly the same size, or better, a Pareto point that evenly distributes the solutions in each of the regions.
Conclusion
In this post, we concluded our discussion of the partitioned guided improvement algorithm. We had previously discussed the background and inspiration for PGIA, and in this post, we completed the algorithm and walked through an example execution. The algorithm is far more complicated than OGIA, but it guarantees no duplicate solutions.
At this point, the blog series has covered all the work our group has accomplished so far. I have no further blog posts planned for this series, as they will depend on what our group works on, from now until March 2014. However, potential topics include the results of our further investigations, or results from rigorous performance evaluations.
Thank you for reading this blog series. I hope the posts have been informative and interesting, and that it was worth your time. If you still want to learn more, you can look at our documents and repositories.
I would like to thank Talha Khalid, Chris Kleynhans, Zameer Manji, and Arjun Sondhi for proofreading this post.
Notes
^ Remember, such a solution only exists if it satisfies the problem constraints. However, the possibility of existence is good enough here, because we want to guarantee that no solution exists.
^ That is, a solution in one region cannot dominate a solution in another region. We demonstrated this by identifying the regions a dominating solution could exist in.
^ We do not concern ourselves with the region with
N“worse than” constraints, because we already know all of its solutions are dominated by P.^ This row can be read as “Region
000, with constraint (<10, <11, <9), contains the solution at(5, 6, 4).”^ I tried discussing the implementation details in an early draft, but a high-level description was not very enlightening. I would have to start describing what sort of concurrency constructs we used in Java, but the discussion then becomes tedious.
^ IGIA had very little improvement over GIA for the 9 queens problems, so we never attempted this case, which took over fifty days with GIA.
^ Remember, this is the same CGIA that took just under four hours for 9 queens with 7 metrics, which took over 50 days on the original GIA.
^ We did not attempt these problems with CGIA, because we suspected the tests would take too long.